Introduction
Silicon Valley and the tech industry in general love bandying about buzzwords. Stuff like machine learning, artificial intelligence, deep learning, etc., but really, what exactly is going on? My goal for this post is to provide some insight into one particular implementation of a few of these buzzwords. I will be delving a bit into the mathematics behind how this stuff works, but hopefully in such a way that it remains accessible.
Machine learning is really just about taking a statistical model1 and having it improve based off more data. In machine learning, there are two crucial details you should know about any model; they are the sole factors deciding what any algorithm can and will actually do:
- What was the data that the model was trained off of?
- What is the model trying to do?
In this post, I train a machine learning model off a data set of cookie policies from eight websites2. I aimed to use the model by feeding in some new cookie policy not found in the original data set and figure out which sentences stood out the most as being weird. My idea was that the most abnormal sentences in a cookie policy would be the ones you would most want to pay attention to.
Before I do that, I’d like to give a brief overview of what I’m doing and dive into what’s going on behind the scenes. But before I even do that though, I first need to explain what a vector is.
So What The Hell Is A Vector, Anyways?

(Sorry, not this guy)
First off, for our purposes, a vector is just a line. This is an oversimplification that will get me crucified by folks who’ve taken a linear algebra course before, but I ask them to please put down the pitchforks for now.
There is an entire field of mathematics devoted to the study of vectors called linear algebra3. A full overview of that field is a bit beyond the scope of this post, so I’ll be focusing instead on a working understanding of what they are and why they’re useful4.
Visualizations of vectors

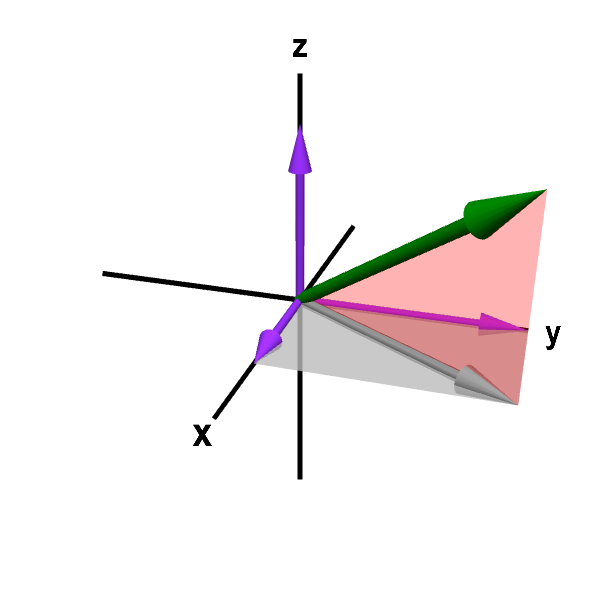
Vectors store information.
That’s their job. In the case of the first vector , we’re connecting the coordinates \((0, 0)\) and \((4, 3)\) with a line. That information is stored within the vector. But we can also add dimensions to store more information. Dimensions are just slots to put in numbers to store extra information. In the second image, we have a third slot for numbers, but after that our visualization techniques for vectors kinda start to fail and break down. But mathematically showing it for four, five, six, or even a million dimensional vector is actually pretty straightforward. We just add extra slots.
Using mathematical notation, our two-dimensional vector would look like \(\langle4,3\rangle\). What this is saying is that in order to get to our destination, we want to move four units in the first dimension and then three units in the second dimension. A ten dimensional vector would look like this \(\langle1,2,3,4,5,6,7,8,9,10\rangle\) for example. So to get where we want to go, we need to travel one unit in the first dimension, two in the second, three in the third, and so on until we get to the tenth dimension where we need to travel ten units. To represent the space (more formally called a vector space) that our two-dimensional vector lives in, we’d say it lives in \(\mathbb{R}^2\), or r-two. What we’re saying here is that we’ve got two slots to represent information, and each slot is a number that exists in reality.
A brief tangent on numbers
While I previously mentioned numbers that exist in reality, in actuality these numbers are a bit more complicated than that. When I say real, what I’m actually referring to are the real numbers, or the ‘reals’ for short. The reals are what you generally think of when you think ’number.’ Not just the integers, which are whole numbers like \(1, 2, 3…\) etc. (although those are included in the reals), but everything. Decimals like \(5.21390321\), numbers where a decimal equivalent would go on forever like \( \frac{1}{3} \) (\(0.333333…\)) or pi (\(3.1415926…\)), all of these are considered real numbers.
What other numbers could exist? Well, you also can have imaginary numbers, which are numbers like \(\sqrt{-1}\) that can’t exist using real numbers. For the case of the square root of negative one, no matter what you do, you can never find a real number that can multiply by itself to reach negative one. If you have a negative multiplied by itself, it becomes a positive (\(-1*-1=1\)), and a positive multiplied by itself is also positive (\(1*1=1\)). So the outcome of multiplying a number by itself is always positive. As a result, mathematicians invented imaginary numbers to represent those numbers. Imaginary numbers have some pretty cool applications that go way, way beyond the scope of this post, but for those interested, this is a cool video and an interesting article on the topic.
Why The Hell Do We Care About Vectors, Anyways?
Computers don’t understand what words mean.

For one, all the letters on your screen need to be converted into numbers for computers to be able to work with them. To a computer that uses ASCII
to encode meaning, Hello is the same thing as \(072\ 101\ 108\ 108\ 111\). But that’s just storage, and the actual meaning behind Hello is completely lost to the computer. So, some clever folks started putting their brains together, and realized… hold on a second…
What if we turned these words into vectors?
The biggest limitation in just using numbers (like \(072\ 101\ 108\ 108\ 111\)) is the amount of information that you can use to represent the object in question. But with vectors, to store some more information we just tack on extra dimensions. \(\langle3, 4\rangle\) doesn’t store all the information we want? Fine, we’ll just add an extra slot! So we could use \(\langle3,4,9\rangle\), or \(\langle3,4,9,8\rangle\), and so on and so forth. With this extra space, we can now try to encode the meaning of things.
To summarize, by using vectors we can (attempt to) encode the meaning of words, since vectors can store a lot more information than stand-alone numbers can.
Okay, But How?
There’s a huge number of ways to encode the meaning of words. This process is called ‘text vectorization’ (because we are turning text into vectors) or ‘text embedding’. One of the most simple ways to do it is just by creating some gigantic space with, say, ten thousand dimensions. Each dimension would then have its own word assigned to it. So dog might be \(\langle0, 0, 0, 0, 0, 1, 0, 0,…\rangle\), cat might be \(\langle0, 0, 0, 0, 0, 0, 0, 1,…\rangle\), and so on. This is called a ‘Bag of Words’ (BoW) approach. The idea is that by just storing which words show up and how often, we can generate meaning that way.

This completely ignores grammar, word order, and a lot of other information, as well as has a lot of wasted information. If we have ten thousand words we need to represent, each word vector is going to have 9,999 slots that are empty. Some other problems: what if we have unique words? What if we have misspellings? What if we’re making new words, or hyphenating words, or any number of other things that language allows us to do? By using this strategy, each word has to have a unique dimension, and if the word doesn’t exist, then we don’t have any way of dealing with it.
We then train our algorithm by shoving in a whole load of data, and tell the algorithm to make sense of all the different vector representations of words. In essence, machine learning algorithms just look for patterns in vectors, then use this to generate some output.

Another way of encoding the meaning of words is by looking at neighboring words as well as the words themselves. So for example, say we have a sentence like ‘I drive my motorcycle to the beach.’ And we have another sentence like ‘I drive my car to the beach.’ Because motorcycle and car are both found surrounded by similar words, their meaning might be a lot closer to each other. So the vector is altered a little bit to be more similar. And this has domino effects all the way down the line. As you ’train’ your data set with more and more sentences, more complex meaning can be encoded. This meaning is encoded by changing the numbers in each vector to be closer to what it observes in the data set that the model is trained on. Through this, we can have a more nuanced understanding of words and sentence structure that a Bag of Words approach would otherwise fail. This is the type of strategy that Text2Vec takes in encoding meaning.
And finally, we get into the strategy that I used on my project, which was the fastText approach. First off, I’d like to clarify something: I am an absolute novice when it comes to machine learning and natural language processing (the stuff we’re doing here), and the math behind this stuff (even techniques like Bag of Words) turns out to be surprisingly complex. If you want a higher level overview of what’s going on, I’m pretty much just summarizing the information I read in the documentation and this really informative medium post . Feel free to check out the sources directly.
FastText is a furthering of Text2Vec, except that in addition to doing everything that Text2Vec does, it also makes use of ‘character level information.’ What this means that not only does the strategy look at neighboring words as well as the words themselves, each word is then broken down into pieces of the word. How large or small this piece varies on how we want to implement the strategy (the more we break down, the higher level meaning but also the more data it takes to store the vector), but if we wanted to break down letter by looking at 3-character pieces, our collection would contain the word itself as well as let, ett, tte, and ter. This allows information like prefixes and plurals and other such constructs to be understood separately from just as it appears for the words themselves.
So for example, where Text2Vec could figure out that dog and dogs are similar words because they’re surrounded by some of the same words, fastText would realize that ’s’ on the end of a word means that it is plural, and that everything else is pretty much the same word. FastText could also figure it out the same way that Text2Vec did. This also helps with misspellings! Say I’m a letter off of one word; fastText would look at the context and say “hmm… we don’t have a word for this, but I noticed that the characters are really close to this other word, I’m going to take a guess and say that they have pretty similar meanings.” This also helps with more complicated, rare, or unique words that never showed up in the original data set that the model was trained on. Since cookie policies are legal agreements, I figured they’d have quite a few more obscure words, compounded even further by the fact that they’re legal agreements written by techbros. As a result, I felt that fastText would be the most valuable strategy for this project.
Now It Is Time For The Doing Of The Thing
Phew. Congratulations on making it past over two thousand words of background information! Seriously, this is some complex stuff, so good on you for making it thus far. We’re finally going to get into the implementation of How I Did The Thing, as well as displaying proudly my (rather terrible) code.
The Data Set

The first and most important thing to any machine learning project is to gather the data set you want to train your algorithm on. Since finding a thousand cookie policies to create the data set would’ve been rather difficult (this would’ve required web spyders, a ton of parsing, and enormous patience), I instead just manually gathered the cookie policies of eight highly-trafficked sites (Amazon, Facebook, Google, LinkedIn, Pinterest, TikTok, Twitter, and Wikipedia) and cleaned them up a bit before plopping them into a .txt file.
The Libraries
In programming, you often want to use other people’s stuff. They put their stuff in libraries that other folks (like us!) can use. For this project, we’re using four libraries: fastText , String , NumPy , and pandas .
import fasttext
import string
import numpy
import pandas
As mentioned previously, we’re using fastText to train our model. String is a standard library (a library that contains stuff that is made available across every iteration of the language. In other words, no matter what, String will always be supported) that allows us to better work with text. I use String to clean up our text to get something useful out of it. NumPy (short for Numerical Python) is a library that provides support for the big vectors that we’re going to need to be using in this project. Pandas is a data analysis library, and I use it to provide a cleaner, sorted visual for the data we output. This is sometimes called data visualization.
Training the Model

model = fasttext.train_unsupervised('data.txt', model='skipgram', dim=100, epoch=3)
model.save_model("cookie_model.bin")
This is where we train the model. We’re inputting a .txt file that contains the cookie policies of the eight major websites previously mentioned. We’re choosing the skipgram model as opposed to the continuous bag of words approach (CBoW). The difference, as stated in the fastText documentation
is that skipbow predicts target words with nearby words, whereas cbow predicts words according to context.
Let us illustrate this difference with an example: given the sentence ‘Poets have been mysteriously silent on the subject of cheese’ and the target word ‘silent’, a skipgram model tries to predict the target using a random close-by word, like ‘subject’ or ‘mysteriously’. The cbow model takes all the words in a surrounding window, like {been, mysteriously, on, the}, and uses the sum of their vectors to predict the target. The figure below summarizes this difference with another example.
‘Dim’ refers to the dimension of the vector. In this case, we’re operating in \(\mathbb{R}^{100}\). In other words, all our vectors have one hundred slots for real numbers to be stored in. The higher dimension, the more data we can represent, but consequently the model takes longer to train, takes up a lot more space, and requires a lot more work to run.
‘Epoch’ refers to the number of times the model will train on the data set. An epoch of three means that we’re going to run through our data set three times before it completes.
After that, the next line of code is just telling the program where we want to put our model. In our case we’re storing it as cookie_model.bin, and it will be dropped in whatever folder the file executing the code is in.
Using the Model
Full Code
model = fasttext.load_model("cookie_model.bin")
file_content = []
parsed_content = []
sentence_vectors = []
vector_magnitudes = []
all_data = []
sentence_dict = {}
with open('comparison_input.txt') as f:
file_content = f.read()
for sentence in file_content.split('.'):
parsed = [word.strip(string.punctuation) for word in sentence.split() if word.strip(string.punctuation).isalnum()]
if len(parsed) < 2:
continue
parsed_content.append(parsed)
for sentence in parsed_content:
sentence_string = ' '.join(sentence)
sentence_vector = model.get_sentence_vector(sentence_string)
sentence_vectors.append(sentence_vector)
magnitude = numpy.linalg.norm(sentence_vector)
vector_magnitudes.append(magnitude)
sentence_dict.update({sentence_string: magnitude})
df = pd.DataFrame.from_dict(sentence_dict, orient="index")
df.to_csv("output.csv")
Now that we collected the data, trained the model, and figured out a cookie policy we want to analyze, it’s finally time to use our model!
model = fasttext.load_model("cookie_model.bin")
First things first, we have to load the model. We originally saved it in the previous code snippet under the file name of cookie_model.bin, so we’re just going to direct the program towards our model.
file_content = []
parsed_content = []
sentence_vectors = []
sentence_dict = {}
These are all the different variables we’re going to wind up needing in this snippet, and I’ll explain what each is being used for as we get deeper into the code.
with open('comparison_input.txt') as f:
file_content = f.read()
This is our input data. In this case, I’m using the Discord cookie policy
. I’m telling Python that I want it to read this .txt file, then store it as the file_content variable we defined earlier.
for sentence in file_content.split('.'):
parsed = [word.strip(string.punctuation) for word in sentence.split() if word.strip(string.punctuation).isalnum()]
if len(parsed) < 2:
continue
parsed_content.append(parsed)
This is where we start parsing. First things first, I’m saying that I want to separate our file content into a bunch of different sentences, and I’m saying that the thing that decides the space between sentences is a period.
I ask Python to loop through each of these sentences, and then parse out everything that isn’t a word. This leaves us with our sentence — which is really just a list of words. If the sentence only has one word (for example, if it caught a URL or ellipses or other such usage of periods that don’t demarcate the end of a sentence), we tell Python not to save our sentence into the array of parsed sentences called parsed_content.
for sentence in parsed_content:
sentence_string = ' '.join(sentence)
sentence_vector = model.get_sentence_vector(sentence_string)
sentence_vectors.append(sentence_vector)
magnitude = numpy.linalg.norm(sentence_vector)
sentence_dict.update({sentence_string: magnitude})
This is the juicy part of the script! In the first line, we put our sentence back together, then we ask our model for the vector equivalent of our sentence. On the third line, we put that vector into our array of vectors — we don’t do anything with the array of sentence vectors in this project, but we could if we wanted to do more fancy things.
Here we take the magnitude of the vector, or in other words we take the length of the vector. Do you remember \(a^2+b^2=c^2\) from high school? What that is essentially doing is finding the length of a vector with coordinates \(a\) and \(b\). And guess what? As it turns out, this works for further dimensions too! We just keep adding variables on the \(a^2+b^2\) side.
Our magnitude, or ’norming’ formula now looks like \(\sqrt{a^2+b^2+c^2…}\) for each dimension in our vector. The reason we’re calculating vector lengths is that weirder sentences will have shorter vector lengths, since our model is unsure precisely what’s going on in them, since they’re not as represented in the data set.
Finally, we add the sentence string and magnitude to our dict (essentially an unordered list that is better at handling large amounts of data) for storage and repeat this for every sentence in our input file.
df = pd.DataFrame.from_dict(sentence_dict, orient="index")
df.to_csv("output.csv")
Here we tell pandas to pop our dict into output.csv.
“Data Visualization”
![]()
import pandas as pd
df = pd.read_csv("output.csv")
sorted_df = df.sort_values(by=["norm"], ascending=True)
print(sorted_df)
Here we’re reading our output and then sorting the values by the magnitude (also known as the norm) in ascending order so that we see the weirdest sentences first. After that, we print the results to the console. Data Visualization is in quotes because I’m pretty terrible at that. All I’m doing is sorting the data and throwing it into the console; pandas is capable of so, so much more.
Results
sentence norm
11 You can find instructions for how to manage Co... 0.898231
16 You can learn more at Network Advertising Init... 0.954725
3 The services use the following types of cookie... 0.999688
17 Depending on where you are accessing our servi... 0.999935
10 You will need to manage your settings for each... 0.999939
8 Manage cookies To control how information is c... 0.999941
4 If you try to use tools to disable these cooki... 0.999953
15 Third party groups also enable you to limit ho... 0.999961
12 To disable analytics cookies you can use the b... 0.999963
20 Questions or concerns about your privacy You c... 0.999964
2 You can control cookies as described in the to... 0.999965
18 If you disable or remove cookies some parts of... 0.999968
7 Performance Cookies These allow us or our anal... 0.999968
1 cookies are placed by us and our service provi... 0.999969
6 Disabling these could affect some service func... 0.999972
19 Information may be collected to remember your ... 0.999973
0 We may receive information from cookies small ... 0.999977
14 Your device may also have settings to control ... 0.999980
5 Functional Cookies These help us provide enhan... 0.999981
9 You can disable and manage some cookies throug... 0.999982
13 Your mobile device may also include browser se... 0.999983
There are a few ways we can interpret these results. First, let’s look at the two sentences that our model is telling us are outliers:
'You can find instructions for how to manage Cookies in popular browsers such as Internet Explorer Firefox Chrome Safari iOS Safari Mac and Opera': 0.8982306
'You can learn more at Network Advertising Initiative the Digital Advertising Alliance and for users in the EU the European Interactive Digital Advertising Alliance': 0.9547247
For the first sentence, we can interpret this as other companies not detailing instructions on how to manage cookies. We can also interpret this as other companies not using specific browsers in their cookie policies, which would add a bunch of unique words and weirdness to the sentence vector. Or perhaps even a combination of the two — our model isn’t quite advanced enough to tell us exactly why this part of the cookie policy is so weird.
For the second sentence, we can interpret this similarly to the first: that other companies do not have as many external sources of knowledge.
The fact that all the other sentences are pretty ’normal’ might tell us that this is a standard cookie policy — that there really isn’t much here far and away from the usual of tech companies. Ultimately, the problem with operating on such a small data set is that any conclusion we have is biased by the limitations of our training data.
What Next?

There are a few problems with our implementation, which can and should be fixed if we were to create an ‘ideal version’ of this model. An ‘ideal version’ would be able to, with high accuracy, detect outliers in sentences. It should take into account punctuation (this implementation parses that out), otherwise innocent sounding word choice, and other things that we might not see at a first glance. Used properly, this tool would allow people to read a cookie policy or terms of service agreement and allow a more in depth understanding of what’s going on. For the lazy among us, it would allow us to ‘skip to the good parts’ and focus on what matters.
To fix it, there are a few things we could explore:
- Generate a larger data set of cookie policies for a better model
This is the obvious: more data = better model. With more data, our model would have more information on what the ‘average’ cookie policy looks like, which would mean our outliers are much more likely to actually be outliers.
- Explore other types of text embedding strategies and compare the results
In this post, I only explore fastText — there are other text vectorization strategies that could yield similar or even better accuracy. In comparing other models, we could figure out what works best for our use case.
- Explore other outlier detection strategies and compare the results
For this strategy, all I did was norm the sentence vector and sort. While this worked okay, there are many, many outlier and novelty detection strategies that exist. Different implementations could yield different accuracy, or perhaps even completely different and more interesting results!
Conclusion
In summary, while the actual model leaves much to be desired (understandable given the size of the data set), one of the primary goals for this project was to learn more about natural language processing and machine learning. And in that regard, it was a massive success. Going forward, if this model were to actually find use, we’d need to gather a lot more data. We’d likely have to do that using Spyders/Crawlers (I might describe how to make them in a future post), which would be a massive pain in the behind — however, it’d be possible.
I will very likely revisit this project at some point in the future. In the meantime, I would recommend against attempting to make any decisive conclusions using this model. While I mentioned what the possible benefits of a fully realized version of this could entail (a much deeper understanding of your legal rights), due to the size of the data set, this is not that. It’s a fun project, and if you’re at all interested I definitely recommend following along and implementing your own version using the data set (or perhaps adding to it and making it fully your own!).
Thank you for reading, and please contact me if you have any suggestions, criticism, corrections or other feedback.

Statistical models are what you get when you combine statistics and mathematical models: you take past data and use it to try to predict future data. If you’re interested in more information, Wikipedia actually has a pretty solid article on it. ↩︎
This is not quite a sufficient data set to generate impressive conclusions from, but the point of this project was more to further my understanding of machine learning. Click here for the full data set. Originally the goal was to use Terms of Service agreements, but due to the massive amount of text involved, we would have needed a lot more data than merely eight samples. ↩︎
If you’re interested in learning more about linear algebra, this lecture series by Gilbert Strang is a great free resource — Gil is hilarious, enthusiastic, and an overall fantastic teacher. I used this series to get into linear algebra, and I can’t recommend it enough. ↩︎
As it turns out, pretty much the entirety of our modern computing infrastructure is dependent on vectors, which makes them really, really useful. ↩︎